


随着大数据技术的飞速发展,实时计算已成为数据处理领域的重要趋势,作为大数据处理框架Apache Spark的一个子模块,SparkStreaming以其高效、灵活的特质,在实时计算领域扮演着重要角色,本文将重点讨论SparkStreaming在实时计算中的应用与实践,特别是在12月这个时间段内可能面临的挑战和解决方案。
二、要点一:SparkStreaming实时计算概述
SparkStreaming是Apache Spark项目的一个子模块,它扩展了Spark的核心API以支持流数据的处理,通过离散数据流为微批次的处理方式,SparkStreaming能够实现高吞吐量、低延迟的实时计算,它允许数据工程师和科学家以类似于批处理的方式处理流数据,同时保持微批处理的灵活性,这使得SparkStreaming在处理实时数据流时具有高度的灵活性和可扩展性。
三、要点二:SparkStreaming在12月的实时计算应用中的优势与挑战
在每年的12月,由于各种促销活动、节日数据流量激增等原因,数据处理的复杂性显著增加,SparkStreaming的实时计算功能显得尤为重要,其优势主要表现在以下几个方面:
1、高吞吐量和低延迟:SparkStreaming能够处理大量数据,同时保持较低的延迟,这使得它能够应对节日期间的数据流量激增,确保实时响应。
2、灵活的数据处理:通过离散数据流为微批次的处理方式,SparkStreaming允许以类似于批处理的方式处理流数据,使得数据处理更加灵活和高效。
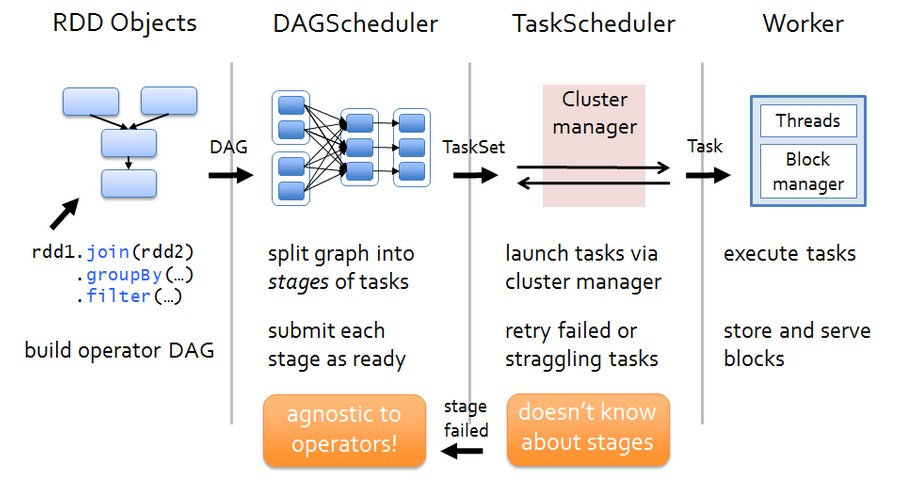
3、良好的扩展性:作为Apache Spark的一部分,SparkStreaming可以轻松集成其他Spark组件,如Spark SQL、MLlib等,以实现更高级的数据处理和机器学习功能。
在12月的实时计算应用中,SparkStreaming也面临一些挑战:
1、数据量的急剧增长:节日期间的数据量急剧增长,对系统的处理能力提出了更高的要求,需要优化SparkStreaming的配置,以提高系统的吞吐量和处理能力。
2、数据处理的复杂性:节日期间的数据类型更加复杂,包含大量的非结构化数据,需要设计更复杂的算法和模型来处理这些数据。
3、资源的合理分配:随着数据量的增长,资源分配变得更加关键,需要合理调度资源,以确保系统的稳定性和性能。
四、要点三:SparkStreaming在实时计算中的最佳实践与优化策略
为了充分发挥SparkStreaming在实时计算中的优势,应对上述挑战,以下是一些最佳实践与优化策略:
1、优化配置:根据数据量、数据类型和系统资源的情况,优化SparkStreaming的配置,包括微批处理的时间间隔、并行度等参数。
2、数据预处理:在数据源端进行数据预处理,以减少后续处理的负担,通过过滤、聚合等操作减少数据量。
3、算法优化:针对实时计算的特点,设计高效的算法和模型,利用Spark的机器学习库MLlib进行模型训练和优化。
4、资源调度:合理调度资源,确保系统的稳定性和性能,利用Spark的集群管理器进行资源分配和调度。
5、监控与日志:建立有效的监控和日志系统,实时监控系统的运行状态和性能,及时发现并解决问题。
SparkStreaming作为实时计算的利器,在应对大数据挑战时具有显著的优势,通过优化配置、算法优化、资源调度等策略,我们可以充分发挥其在实时计算中的优势,应对节日期间的数据处理挑战,随着技术的不断发展,我们相信SparkStreaming将在未来的实时计算领域发挥更加重要的作用。




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...